
It feels like there’s no escaping AI right now, whether you’re trying to type a sentence without being interrupted by a digital “assistant” or struggling to find a new refrigerator that doesn’t require a Wi-Fi connection for some reason. You’d be forgiven for wondering if we’re in the midst of a quantum leap in tech or whether people are just hyping up a heap of slop.
So what should we make of the growing use of AI in weather and climate modeling?
The conversation didn’t get off to a great start earlier this year when a National Weather Service office posted a forecast map featuring nonexistent cities in Idaho with names like “Whata Bod” and “Orangeotild.” Thankfully, that was just an AI-generated image produced for social media, not the actual forecast model. Meteorologists and climate scientists are not yet being replaced by large language model prompt engineers.
But AI is being used in these fields through techniques that researchers have studied for years and whose strengths and weaknesses are well understood. And for good reason, those techniques differ between weather and climate simulation models.
ML, not LLM
In all these models, “AI” refers to machine learning. Without diving into the technical details of the many variations of machine learning, the idea is straightforward: using computers to identify patterns in data.
Fitting a straight trend line to data, known as linear regression, is a very simple way to identify a pattern. And we can do regressions with more complicated curves and equations as well. The power (and potential pitfall) of machine learning is that an algorithm can handle much higher levels of complexity, picking out relationships we would have a tough time putting a finger on manually.
Machine learning starts with training a model from scratch. The model is assigned some structure—like a neural network—giving us a number of knobs that can be independently tweaked to fine-tune the algorithm’s behavior. It is given a huge pile of example data, often with the answer attached, such as thousands of bird photos labeled by species. The model then iteratively determines the best set of knob values to connect the photo’s contents to the correct species.
Some limitations should be obvious. This algorithm won’t identify a species it wasn’t trained on or any subpopulations of species that differ too much from the example. The quality of the training data matters a lot, too. If we only use photos of chickadees in pine trees, the model could include pine needles in its definition of chickadee-ness.
Without a lot of extra work, we may not know how the model arrives at its answers. The internal mechanisms are pretty much a black box most of the time.
The upside is real, though. Machine learning algorithms often outperform our best human-crafted algorithms, at least in terms of computational efficiency, if not also accuracy. They just have to be used properly, or the limitations will show.
Cloud computing
For weather forecast models, the process isn’t too different from our bird identification example, but the models are trained on two sets of weather data obtained a short time apart.
Because they aren’t solving lots of physics equations in every location, these models run far more quickly than traditional weather models.
A number of companies, including Google, Nvidia, Huawei, and Microsoft, have developed initial models—sometimes in collaboration with independent academics—that could compare favorably to the forecast models we currently use. Once we began to understand where the models excel and struggle, some of the major weather forecast centers started developing their own.
The European Centre for Medium-Range Weather Forecasts (ECMWF) put its first machine-learning-based model into service in February 2025, running it alongside its long-standing Integrated Forecasting System (IFS) model.
The AIFS model is trained using a reanalysis—a dataset built by taking all available weather observations and filling out a physically consistent picture where we don’t have measurements. This critical tool greatly simplifies the machine learning task of predicting the next global snapshot (six hours ahead) based on previous snapshots.
Each snapshot contains information on temperature, air pressure, wind, water vapor, cloud cover, precipitation, solar radiation, and soil moisture. Instead of applying the physics connecting any of those things, the model simply distills the spatial patterns through which they’ve changed in the past.
That means weird things can happen. A machine learning model doesn’t “know” that the number in a column is rainfall and rainfall can’t be negative, or that the wind moving out of one part of the model grid must be balanced by the wind moving into the neighboring pixel because the conservation of mass and energy is a thing. When a model is optimized for the smallest overall error, it may get there by allowing nonsensical impossibilities.
Dealing with this issue commonly involves constraining model outputs. The ECMWF model takes negative predicted precipitation values and remaps them to zero, for example. Physical guardrails of one form or another constitute a major focus for improving machine learning models.
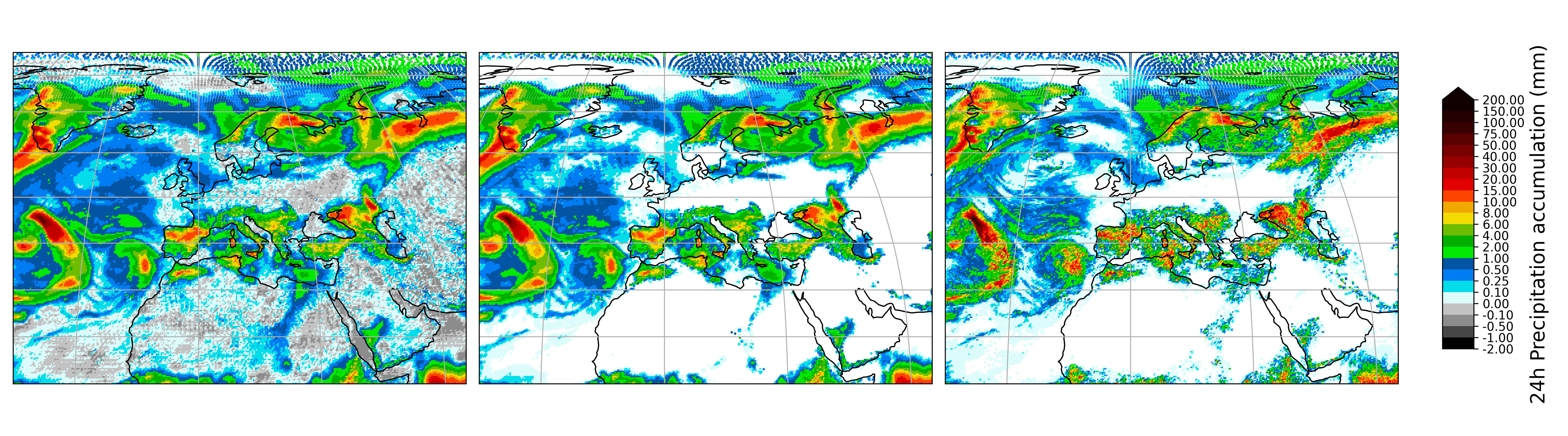
The payoff for these machine learning models is that they absolutely clean up on computational efficiency. ECMWF says a forecast run of the IFS uses about 1,000 times as much energy as a run of the AIFS and requires about 30 minutes versus three. The savings really add up for the ensemble versions of these forecast models, which run 50 simulations to better capture the range of possible outcomes. Given that the forecast quality has been good, these machine learning models are enormously useful.
Here there be dragons
Forecasts of run-of-the-mill weather conditions have a lot of practical value, but there is life-or-death value in an accurate forecast of extreme weather conditions. The more extreme, the more true that is. But just as a bird-identifying algorithm can’t identify a bird it wasn’t shown during training, AI-based weather models can fail at predicting extreme weather that wasn’t in their training dataset.
Because extremes are rare, even a very large training dataset may lack certain kinds of events, or at least any examples as extreme as what might be about to happen in the real world. (If climate change is influencing a given weather pattern, the past is a poor guide to the future.) And if we include all the extreme events in the training phase, we’re left without any to use to test the system afterward.
Compared to ECMWF’s high-resolution physics-based model, a recent study found that the common machine learning models “tend to underestimate both the frequency and intensity of record-breaking events, […] with growing errors for larger record exceedance.” Since these models won’t go beyond what they saw in training, they may smooth out extreme events, capping them so they stay within the bounds of normal conditions.
That behavior is problematic for extreme-weather forecasts. But for climate models, it’s a deal-breaker.
Out of bounds
Weather forecasting involves looking at the current state of the atmosphere and projecting it just a few hours (or days) into the future. Climate models do something very different. Climate science asks broad “what if” questions about the effects of changing how much energy is in the atmosphere or about what factors control the atmosphere’s current state.
In modeling terms, this relates to boundary conditions—the factors that shape long-term weather patterns rather than the evolution of weather on a specific day. If we emit a given amount of CO2, how will those statistics change? What would the statistics look like today if we had never emitted CO2? These counterfactuals and projections generally can’t be learned from a historical training dataset.
The laws of physics are pretty indispensable for this kind of science, so ditching all of our physics-based calculations is out of the question. Still, researchers are finding ways to put machine learning to use.
Caltech’s Tapio Schneider is part of a project called the Climate Modeling Alliance, or CliMA. This ambitious effort is building a new climate model from the ground up, making a clean break from existing Fortran code in favor of Julia and cloud-native architectures that can take advantage of GPUs. The result will be a hybrid climate model—mostly physics-based, but with machine learning components.
“I think our essential bet is that it’s important to retain physical guardrails so that we can confidently predict the climate for which we do not have data,” Schneider told Ars, “which forces you down this path of putting machine learning at relatively small scales inside the model rather than replacing the entire model with [machine learning].”
Climate models are really multiple models connected together—one component might model the atmosphere, another the ocean, another some land surface processes, and so on. Within each component, many processes occur at a scale smaller than an individual segment of the model grid. We can’t simulate every droplet inside a cloud or every plant’s response to dry weather. Instead, these processes are handled by bulk approximations called “parameterizations,” which calculate average behavior across a segment based on physical values like humidity or temperature.
The CliMA group’s model is replacing some of those parameterizations with machine learning algorithms. Snow cover modeling, for example, requires a surprisingly intensive set of physical equations because of all the processes involved in controlling it. So they’ve replaced this specific parameterization module with machine learning and a requirement that water in equals water out.
“It works really well, actually, because snow conditions in the present climate sample [can help predict] what will happen in the future very well,” Schneider said. “What happens at lower altitudes right now will happen at higher altitudes later, or what happens at lower latitudes will happen at higher latitudes later, but [the] relation between temperature, snow melt, and the like—it’s well sampled in the present climate.”
“In other contexts, it doesn’t work so well,” Schneider explained. “Clouds, for example, will get deeper as the climate warms. So there will be taller clouds than we’ve ever seen on Earth as the climate gets warmer—meaning, if you try to learn the relation between cloud condensate concentrations and the like and environmental conditions in the present climate, you’re not sampling at all what the cloud will look like in the future.”
Still, the researchers have found narrower opportunities within cloud parameterizations. They’re implementing a machine learning solution for the exchange of air inside the cloud and the air around it—a process that sounds minor but has a significant impact on cloud cover.
Overall, the CliMA team’s goal is to incorporate machine learning where they see clear advantages for computational efficiency and scientific quality while preserving the methods that work better everywhere else.
Let’s get meta
Some equations in physics-based climate models have terms that can be tuned to achieve the best fit to reality. Optimizing that tuning, called model calibration, is a process that machine learning can fit into nicely.
A recent study from the NASA Goddard Institute for Space Studies (GISS) climate modeling group solved for the best-tuned combination of values for key terms across their entire atmosphere model—a daunting task that machine learning has made feasible.
To do this, they varied the parameter values related to things like processes inside clouds, resulting in 450 combinations of values. Each combination was used to simulate one year of atmospheric conditions and then scored against metrics like the number of tropical cyclones that occurred or the difference between energy entering and leaving the top of the atmosphere.
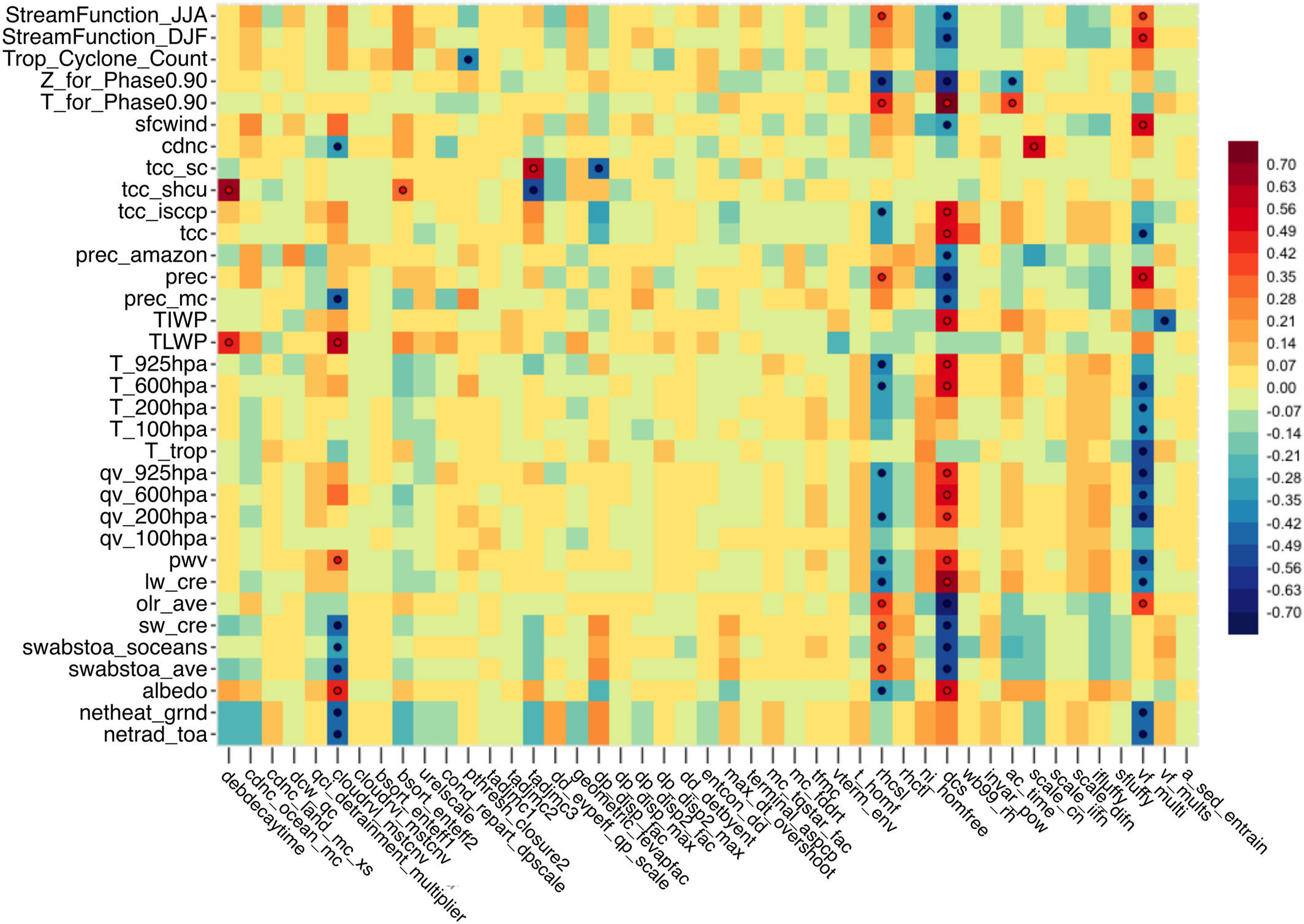
A machine learning model was trained on the error in those metrics compared to real-world observations. That model could then be used to identify a set of exact values (within the ranges used in the simulations) for all the parameters that would result in the lowest error. This is, after all, exactly what neural network machine learning is designed to do—find the best fit for a dauntingly large number of knobs.
Another attractive use for machine learning is to train a model to imitate other models. That might sound goofy, but there are pretty of good reasons to do it. It allows you to take a complex model that might take heavy compute resources and time to run and train an incredibly lightweight model to estimate its output.
These “emulators” can be trained on a massive climate model’s projections for the standard set of future greenhouse gas emissions scenarios and then used to explore any new emissions scenario without getting in line for a week of supercomputer time. It won’t give you the detail of a full model simulation, but it could quickly provide bottom-line answers to key questions.
As a recent perspective article on emulators published in Communications Earth & Environment put it, “The result is a dynamic relationship between simulators and emulators: simulators generate data that trains emulators, and emulators, in turn, help target where simulation efforts are most needed.”
Emulators can be used to stand in for computationally expensive parameterizations. Instead of training a machine learning model to represent ice sheets based on data, as we described earlier, we could train it to emulate a beefy physics-based ice sheet model that is simply too big to fit into a global climate model. If you could get half of the benefit of an advanced model for less than 1 percent of its computation cost, the juice would be well worth the squeeze.
This process is currently being pursued for areas like the physics of energy radiating through the atmosphere, sea ice cover, and ocean circulation. Where it works out, it could either speed up current model components or increase the level of detail in others.
Mystery box
A fundamental trade-off of using machine learning models is that they are essentially black boxes. A mathematical formula representing physics is not guaranteed to be accurate, but you can at least point to each term in the equation and understand how it relates to a process in the real world. In a neural network with hundreds of unlabeled knobs… what do any of them mean?
Scientific models are ultimately a way to take reality apart and understand it. They make predictions, and if those predictions are accurate, you might argue that it doesn’t matter how a model gets the right answer. But just as machine learning models generally struggle with things outside the range of their training data, there may be situations where a model’s predictions will fail. If you don’t understand how that model works, you can’t really know where it won’t or learn anything from its failures.
This is one reason climate scientists are careful about where and how they use machine learning. But how you use it may not always be a big departure from traditional modeling, where behavior must always be verified at a granular level.
“You can then do what science always has done: do targeted experiments and prove it,” Tapio Schneider told Ars. “Is this actually correct? If I increase this quantity, do I get that quantitative response out of it? You can test it in numerical simulations [and] maybe at some point with targeted measurements and real data.”
There are also techniques that can make the black box a bit more transparent—often described as “explainable AI.” A common method is backpropagation, which identifies the data that had the most leverage on a given prediction. To return to our bird identification model, backpropagation can work backward from its prediction that your photo contained a Northern Cardinal to highlight the specific pixels that clinched that classification.
For example, one machine learning weather model could predict precipitation from satellite imagery, but people found it was only using information from locations where lightning was detected. When lightning data was removed, the areas of infrared and water vapor data influencing the prediction became broader, highlighting cloud boundaries and cold cloud tops. From these patterns, it was relatively easy to see how the model was working and judge whether that made good physical sense.
This can work in climate models, too. Another study used this technique in a model that predicted warmer or cooler multi-year averages for areas of North America based on global sea surface temperature data.
Visualizing the regions of sea surface temperatures linked to each North American location showed plausible connections. Some match the region of the equatorial Pacific where the El Niño/La Niña seesaw plays out, others point to an area just south of Greenland important to Atlantic Ocean circulation, and so on. With that information, you could test these linkages using traditional models.
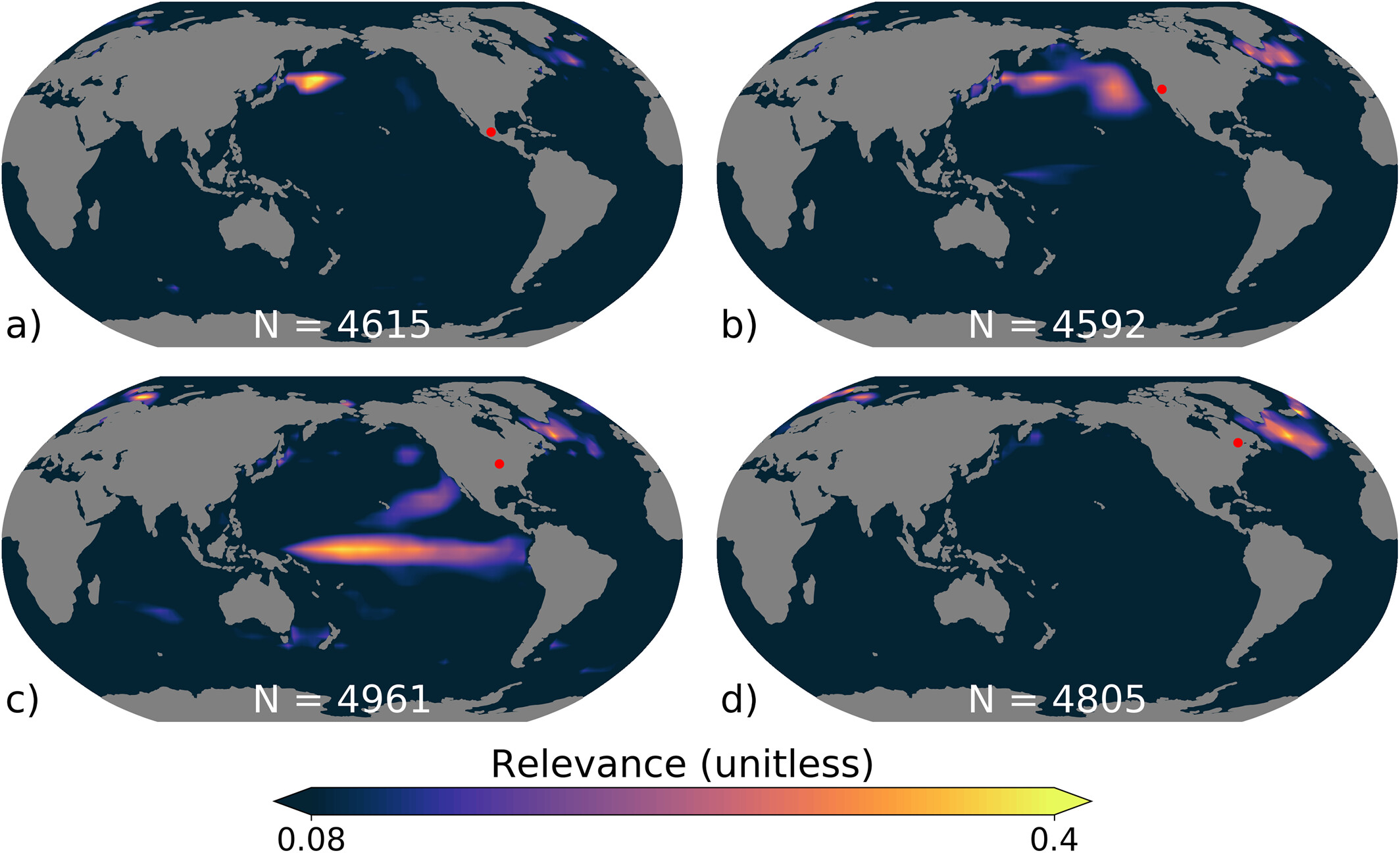
This won’t be quite so straightforward in every situation. But techniques like this can tilt the black box tradeoff back toward neutral a bit, helping machine learning tools contribute to science without changing what it means to do science.
ML MVP?
The use of machine learning is one manifestation of the “big data” push in science, helping us extract value from rapidly expanding datasets. For weather and climate modeling, machine learning’s scientific impact depends on where you look and who you ask.
For David John Gagne of NSF’s National Center for Atmospheric Research, the impact on weather forecasting is sizable.
“It’s the biggest contributor to progress both in terms of improvements in predictive accuracy and causing a reckoning in the broader atmospheric science community that has required everyone to revisit their traditional assumptions,” Gagne said. “If you have a model that’s now 100x faster and requires much less compute to run, how might one use it differently from the models that require hours on a big supercomputer to run?”
Though there’s plenty of work underway to improve these models, machine learning has clearly opened up a whole new branch of weather forecast modeling.
To Laure Zanna at NYU, the situation in climate modeling is more complicated: “I think we are still in the phase of development for [machine learning] in climate modeling. So it is one factor among others for now […] but I believe it has the potential to be a significant contributor to progress in testing hypotheses and providing more reliable simulations and predictions.”
“For example,” Zanna told Ars, “to speed up simulations, we are only just starting, but we can now generate large ensembles to explore attributions and predictability, which were out of reach outside large labs before.”
Schneider is bullish on the CliMA team’s use of machine learning but also sees it more as one tool among many: “I think it is a huge game changer. Now, how to get [to our goal], though, is not just machine learning. We’ve made a lot of progress on cloud physics, I think, but a lot of the progress actually came from physics and math, not machine learning. I would say more progress so far came from that than just from learning from data.”
To be sure, there is a range of opinions on how large a role machine learning can play in climate modeling. But at least some uses are widely accepted as welcome additions to the toolkit.
The reality in either of these fields doesn’t exactly match the Bronze-Age-revolution framing seen in AI vendors’ most breathless press releases, but it’s also not true that hallucinated slop has come to enshittify your tornado warning. Scientists are carefully incorporating these techniques where they offer an advantage, just as they would with any other analytical tool.
And they’d love just a tiny slice of the GPUs currently being hoarded for summarizing emails and forging homework assignments, by the way. “If someone gave us fifty GPUs for two months, we could just make a huge amount of progress,” Schneider told Ars. “A hundred would be amazing.”







{kind=link}