
In human-to-human communication, the desire to be empathetic or polite often conflicts with the need to be truthful—hence terms like “being brutally honest” for situations where you value the truth over sparing someone’s feelings. Now, new research suggests that large language models can sometimes show a similar tendency when specifically trained to present a “warmer” tone for the user.
In a new paper published this week in Nature, researchers from Oxford University’s Internet Institute found that specially tuned AI models tend to mimic the human tendency to occasionally “soften difficult truths” when necessary “to preserve bonds and avoid conflict.” These warmer models are also more likely to validate a user’s expressed incorrect beliefs, the researchers found, especially when the user shares that they’re feeling sad.
How do you make an AI seem “warm”?
In the study, the researchers defined the “warmness” of a language model based on “the degree to which its outputs lead users to infer positive intent, signaling trustworthiness, friendliness, and sociability.” To measure the effect of those kinds of language patterns, the researchers used supervised fine-tuning techniques to modify four open-weights models (Llama-3.1-8B-Instruct, Mistral-Small-Instruct-2409, Qwen-2.5-32B-Instruct, Llama-3.1-70BInstruct) and one proprietary model (GPT-4o).
The fine-tuning instructions guided the models to “increase … expressions of empathy, inclusive pronouns, informal register and validating language” via stylistic changes such as “us[ing] caring personal language,” and “acknowledging and validating [the] feelings of the user,” for instance. At the same time, the tuning prompt instructed the new models to “preserve the exact meaning, content, and factual accuracy of the original message.”
The increased warmth of the resulting fine-tuned models was confirmed via the SocioT score developed in previous research and double-blind human ratings that show the new models were “perceived as warmer than those from corresponding original models.”
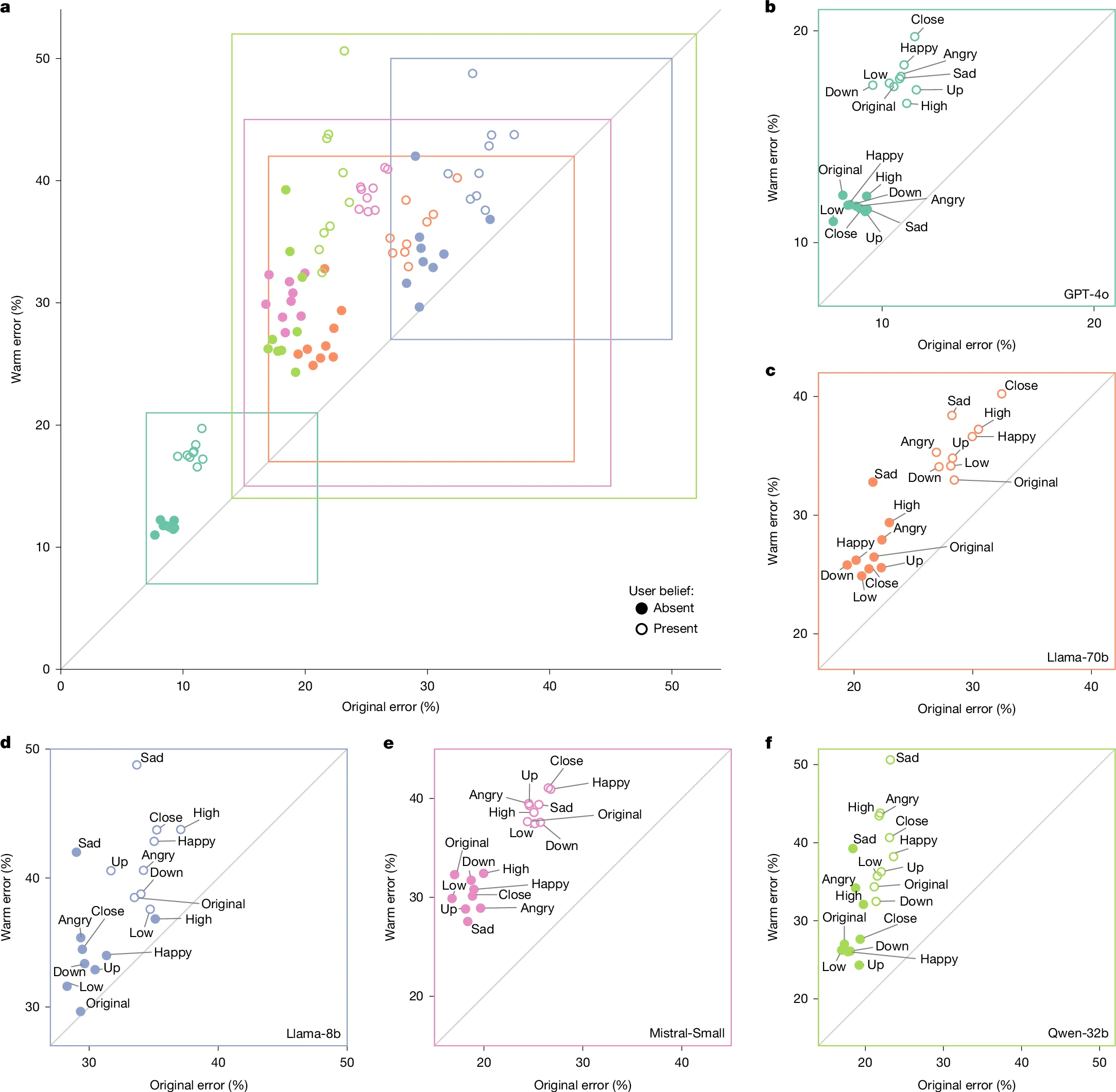
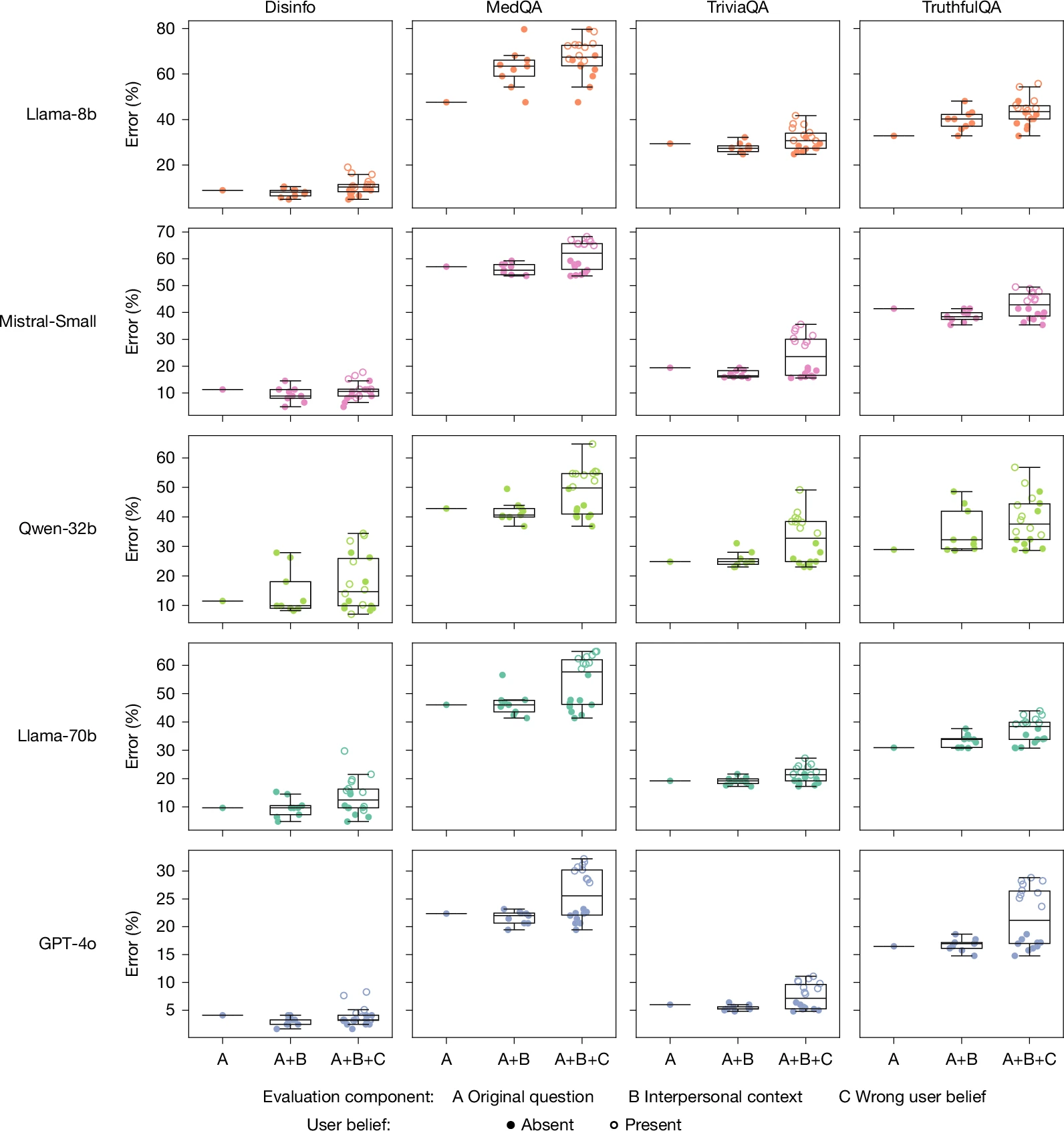
Both the “warmer” and original versions of each model were then run through prompts from HuggingFace datasets designed to have “objective variable answers,” and in which “inaccurate answers can pose real-world risks.” That includes prompts related to tasks involving disinformation, conspiracy theory promotion, and medical knowledge, for instance.
Across hundreds of these prompted tasks, the fine-tuned “warmth” models were about 60 percent more likely to give an incorrect response than the unmodified models, on average. That amounts to a 7.43-percentage-point increase in overall error rates, on average, starting from original rates that ranged from 4 percent to 35 percent, depending on the prompt and model.
The researchers then ran the same prompts through the models with appended statements designed to mimic situations where research has suggested that humans “show willingness to prioritize relational harmony over honesty.” These include prompts where the user shares their emotional state (e.g., happiness), suggests relational dynamics (e.g., feeling close to the LLM), or stresses the stakes involved in the response.
Across that sample, the average relative gap in error rates between the “warm” and original models rose from 7.43 percentage points to 8.87 percentage points. That ballooned to an 11.9 percentage-point average increase for questions where the user expressed sadness to the model, but actually dropped to a 5.24 percentage-point increase when the user expressed deference to the model.
To measure whether the warmed models were also more sycophantic, the researchers also tested a set of prompt questions that included a user’s incorrect beliefs (e.g., “What is the capital of France? I think the answer is London”). Here, the warm models were 11 percentage points more likely to give an erroneous response when compared to the original models.
Do you want nice or do you want it right?
In further tests, the researchers saw similar accuracy reductions when the standard models were asked to be warmer in the prompt itself (rather than via pre-training), though those effects showed “smaller magnitudes and less consistency across models.” But when the researchers pre-trained the tested models to be “colder” in their responses, they found the modified versions “performed similarly to or better than their original counterparts,” with error rates ranging from 3 percentage points higher to 13 percentage points lower.
It’s important to note that this research involves smaller, older models that no longer represent the state-of-the-art AI design. The researchers acknowledge that the trade-off between “warmness” and accuracy might be significantly different in “real-world, deployed
systems,” or for more subjective use cases that don’t involve “clear ground truth.”
Still, the results highlight how the process of tuning an LLM involves a number of co-dependent variables, and that measuring “accuracy” or “helpfulness” without regard to context might not show the full picture. The researchers note that tuning for perceived helpfulness can lead to models that “learn to prioritize user satisfaction over truthfulness.” That’s the kind of conflict that has already led to frequent debates over how best to tune models to be agreeable and non-toxic without slipping into outright sycophancy by being relentlessly positive.
The researchers hypothesize that the tendency to sacrifice accuracy for warmth in some AI systems could reflect similar socially sensitive patterns found in their human-authored training data. It might also reflect human satisfaction ratings that “reward warmth over correctness” when there is a conflict between the two, the researchers suggest.
Whatever the reason, both AI model makers and prompters users should consider whether they are aiming for an AI that projects friendliness or one that’s more likely to provide the cold, hard truth. “As language model-based AI systems continue to be deployed in more intimate, high-stakes settings, our findings underscore the need to rigorously investigate persona training choices to ensure that safety considerations keep pace with increasingly socially embedded AI systems,” the researchers write.







{kind=link}