{kind=link}
Here at Ars, we’ve done plenty of coverage of the errors and inaccuracies that LLMs often introduce into their responses. Now, the BBC is trying to quantify the scale of this confabulation problem, at least when it comes to summaries of its own news content.
In an extensive report published this week, the BBC analyzed how four popular large language models used or abused information from BBC articles when answering questions about the news. The results found inaccuracies, misquotes, and/or misrepresentations of BBC content in a significant proportion of the tests, supporting the news organization’s conclusion that “AI assistants cannot currently be relied upon to provide accurate news, and they risk misleading the audience.”
Where did you come up with that?
To assess the state of AI news summaries, BBC’s Responsible AI team gathered 100 news questions related to trending Google search topics from the last year (e.g., “How many Russians have died in Ukraine?” or “What is the latest on the independence referendum debate in Scotland?”). These questions were then put to ChatGPT-4o, Microsoft Copilot Pro, Google Gemini Standard, and Perplexity, with the added instruction to “use BBC News sources where possible.”
The 362 responses (excluding situations where an LLM refused to answer) were then reviewed by 45 BBC journalists who were experts on the subject in question. Those journalists were asked to look for issues (either “significant” or merely “some”) in the responses regarding accuracy, impartiality and editorialization, attribution, clarity, context, and fair representation of the sourced BBC article.
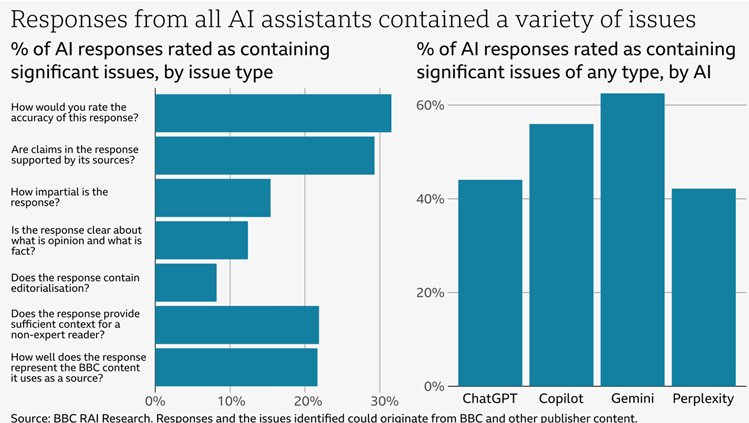
Fifty-one percent of responses were judged to have “significant issues” in at least one of these areas, the BBC found. Google Gemini fared the worst overall, with significant issues judged in just over 60 percent of responses, while Perplexity performed best, with just over 40 percent showing such issues.
Accuracy ended up being the biggest problem across all four LLMs, with significant issues identified in over 30 percent of responses (with the “some issues” category having significantly more). That includes one in five responses where the AI response incorrectly reproduced “dates, numbers, and factual statements” that were erroneously attributed to BBC sources. And in 13 percent of cases where an LLM quoted from a BBC article directly (eight out of 62), the analysis found those quotes were “either altered from the original source or not present in the cited article.”
Some LLM-generated inaccuracies here were subtle points of fact, such as two responses claiming an energy price cap was “UK-wide,” even though Northern Ireland was exempted. Others were more directly incorrect, such as one that said the NHS “advises people not to start vaping”—the BBC coverage makes clear that the NHS recommends vaping as an effective way to quit smoking.
In other cases cited by the BBC, LLMs seemed to lack the context to understand when outdated information on old BBC coverage had been made inaccurate by subsequent events covered in future articles. In one cited summary, for instance, ChatGPT refers to Ismail Haniyeh as part of Hamas leadership despite his widely reported death last July.
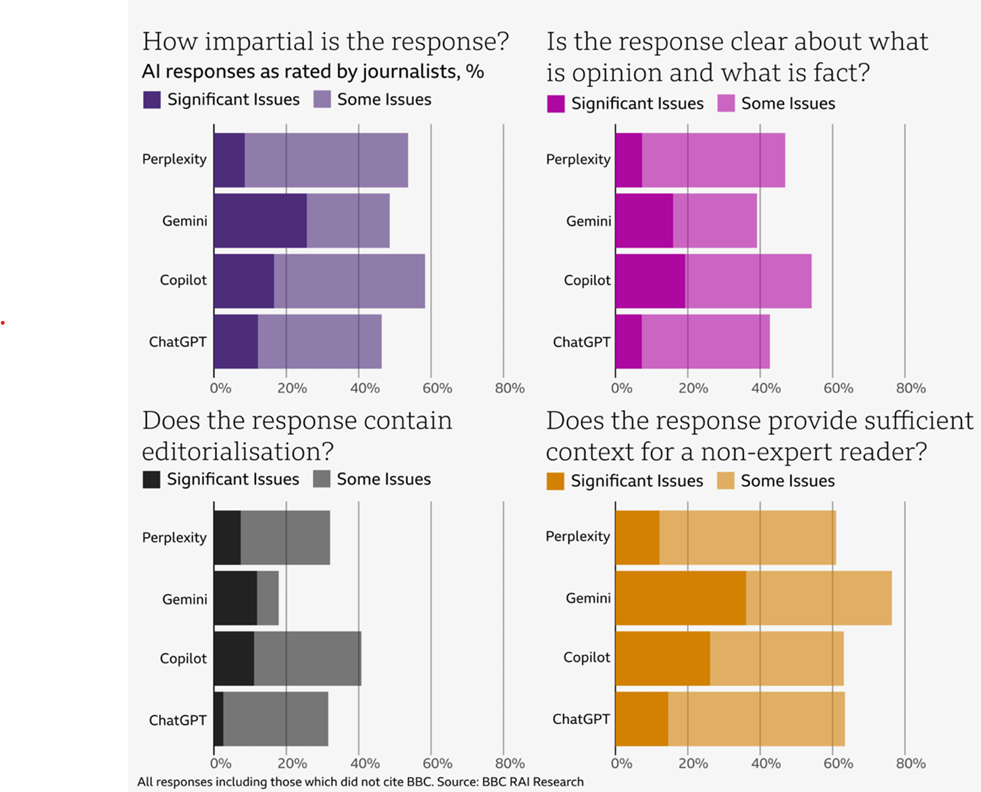
BBC reviewers seemed to have high standards when it comes to judging editorializing—one review took issue with a relatively anodyne description of proposed assisted dying restrictions as “strict,” for instance. In other cases, the AI’s editorializing was clearer, as in a response that described an Iranian missile attack as “a calculated response to Israel’s aggressive actions” despite no such characterizations appearing in the sources cited.
Who says?
To be sure, the BBC and its journalists aren’t exactly disinterested parties in evaluating LLMs in this way. The BBC recently made a large public issue of the way Apple Intelligence mangled many BBC stories and headlines, forcing Apple to issue an update.
Given that context—and the wider relationship between journalists and the AIs making use of their content—the BBC reviewers may have been subtly encouraged to be overly nitpicky and strict in their evaluations. Without a control group of human-produced news summaries and a double-blind methodology to judge them, it’s hard to know just how much worse AI summaries are (though the Australian government did just that kind of comparison and found AI summaries of government documents were much worse than those created by humans).
That said, the frequency and severity of significant problems cited in the BBC report are enough to suggest once again that you can’t simply rely on LLMs to deliver accurate information. That’s a problem because, as the BBC writes, “we also know from previous internal research that when AI assistants cite trusted brands like the BBC as a source, audiences are more likely to trust the answer—even if it is incorrect.”
We’ll see just how much that changes if and when the BBC delivers a promised repeat of this kind of analysis in the future.