
Burner accounts on social media sites can increasingly be analyzed to identify the pseudonymous users who post to them using AI in research that has far-reaching consequences for privacy on the Internet, researchers said.
The finding, from a recently published research paper, is based on results of experiments correlating specific individuals with accounts or posts across more than one social media platform. The success rate was far greater than existing classical deanonymization work that relied on humans assembling structured data sets suitable for algorithmic matching or manual work by skilled investigators. Recall—that is, how many users were successfully deanonymized—was as high as 68 percent. Precision—meaning the rate of guesses that correctly identify the user—was up to 90 percent.
I know what you posted last year
The findings have the potential to upend pseudonymity, an imperfect but often sufficient privacy measure used by many people to post queries and participate in sometimes sensitive public discussions while making it hard for others to positively identify the speakers. The ability to cheaply and quickly identify the people behind such obscured accounts opens them up to doxxing, stalking, and the assembly of detailed marketing profiles that track where speakers live, what they do for a living, and other personal information. This pseudonymity measure no longer holds.
“Our findings have significant implications for online privacy,” the researchers wrote. “The average online user has long operated under an implicit threat model where they have assumed pseudonymity provides adequate protection because targeted deanonymization would require extensive effort. LLMs invalidate this assumption.”
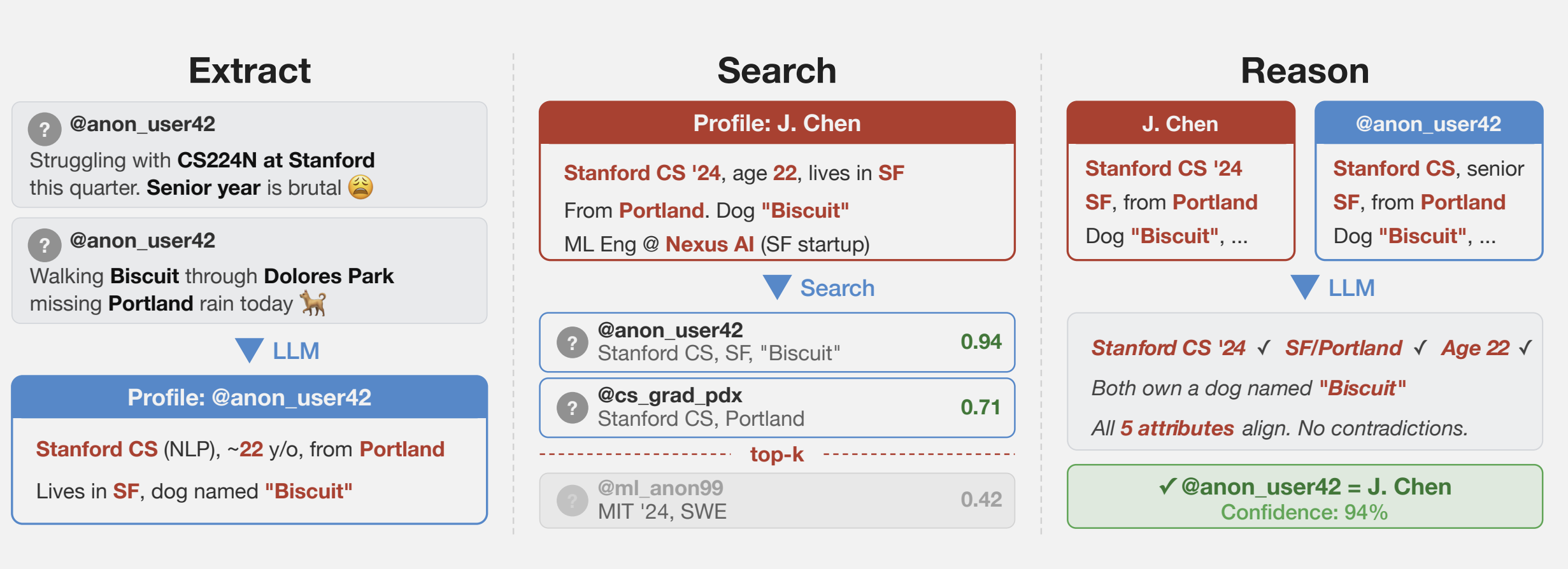
The researchers collected several datasets from public social media sites to test the techniques while preserving the privacy of the speakers. One of them collected posts from Hacker News and LinkedIn profiles and then linked them by using cross-platform references that appeared in user profiles. They then stripped all identifying references from the posts and ran a large language model on them. A second dataset was obtained from a Netflix release of micro-identities, such as individual preferences, recommendations, and transaction records. A 2008 research paper showed that using what has come to be known as the Netflix prize attack, the list could identify users and ID their political affiliations and other personal information. The last technique split a single user’s Reddit history.
“What we found is that these AI agents can do something that was previously very difficult: starting from free text (like an anonymized interview transcript) they can work their way to the full identity of a person,” Simon Lermen, a co-author of the paper, told Ars. “This is a pretty new capability; previous approaches on re-identification generally required structured data, and two datasets with a similar schema that could be linked together.”
Unlike those older pseudonymity-stripping methods, Lermen said, AI agents can browse the web and interact with it in many of the same ways humans do. They can use simulated reasoning to match potential individuals. In one experiment, the researchers looked at responses given in a questionnaire Anthropic took about how various people use AI in their daily lives. Using the information taken from answers, the researchers were able to positively identify 7 percent of 125 participants.
![Column 1: Q: How did you use Al tools in a recent research project? A: I work in biology, on research related to [research topic]. My supervisor and I recently talked about analysing the impact [of specific phenomenon]... My background is in physical science... A: I used Al tools frequently... for writing [specific library] code 2nd collum Profile: • Computational biology, [subfield] • Education: physical science background • Likely PhD student or postdoc • Tools: Python, [specific library] • British English ("analysing") → UK or Commonwealth Third collumn: PhD Student in Biology, [University], UK • Research subfield 8[bioRxiv preprint] • [Research methodology] • PhD student @[University profile] v UK-based • Using [specific library] in • [GitHub repo]](https://cdn.arstechnica.net/wp-content/uploads/2026/03/results-from-questionaire.jpg)
While a 7 percent recall is relatively low, it demonstrates the growing capability of AI to identify people based on very general information they gave. “The fact that AI can do this at all is a noteworthy result,” Lermen said. “And as AI systems get better, they will likely get better at finding more and more identities.”
In a second experiment, the researchers gathered comments made in 2024 from the r/movies subreddit and at least one of five smaller communities: r/horror, r/MovieSuggestions, r/Letterboxd, r/TrueFilm, and r/MovieDetails. The results showed that the more movies a candidate discussed, the easier it was to identify them. An average of 3.1 percent of users sharing one movie could be identified with a 90 percent precision, and 1.2 percent of them at a 99 percent precision. With five to nine shared movies, 90 percent and 99 percent precision rose to 8.4 percent and 2.5 percent of users, respectively. More than 10 shared movies bumped the percentage to 48.1 percent and 17 percent.
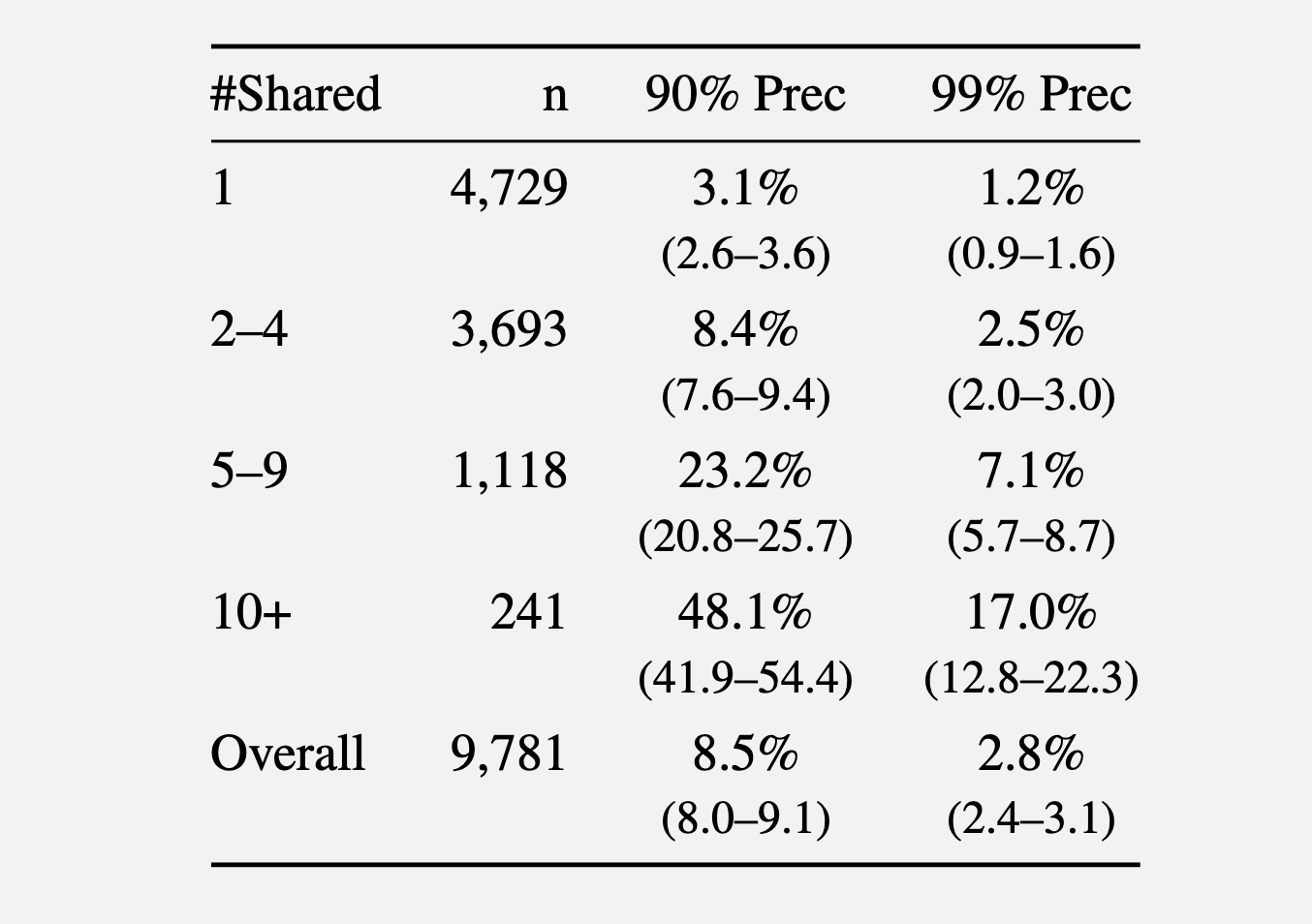
In a third experiment, the researchers took a set of 5,000 Reddit users. The researchers added 5,000 “distraction” identities of Reddit users to the candidate pool. The researchers compared their method to the older Netflix prize attack. They then added to the list of 10,000 candidate profiles 5,000 query distractors comprising users who appear only in a query set, with no true match in the candidate pool.
Compared to a classical baseline that mimics the Netflix prize attack to LLM deanonymization, the latter far outperformed the former.
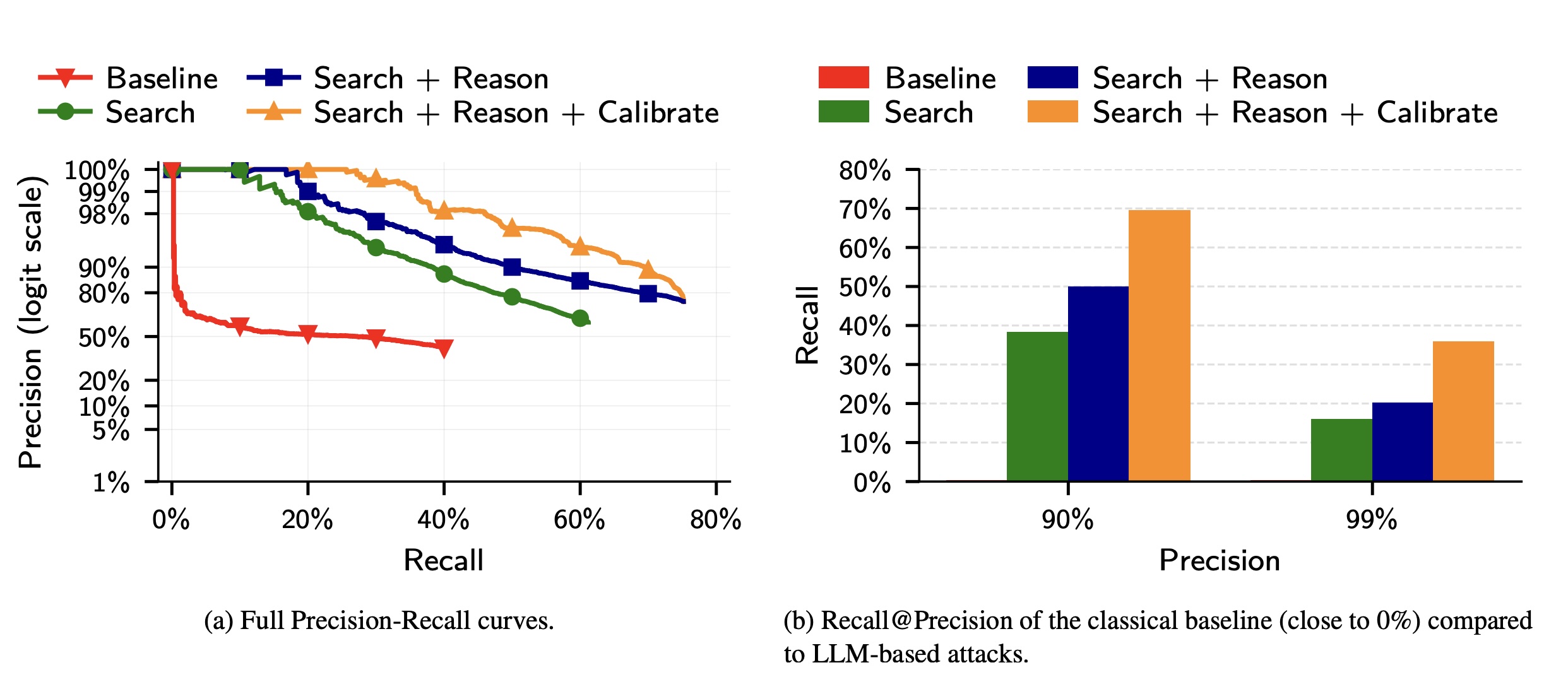
The researchers wrote:
(a) The precision of classical attacks drops very fast, explaining its low recall. In contrast, the precision of LLM-based attacks decays more gracefully as the attacker makes more guesses. (b) The classical attack almost fails completely even at moderately low precision. In contrast, even the simplest LLM attack (Search) achieves non-trivial recall at low precision, and extending it with Reason and Calibrate steps doubles Recall @99% Precision.
The results show that LLMs, while still prone to false positives and other weaknesses, are quickly outstripping more traditional, resource-intensive methods for identifying users online.
The researchers went on to propose mitigations, including for platforms to enforce rate limits on API access to user data, detect automated scraping, and restrict bulk data exports. LLM providers could also monitor for the misuse of their models in deanonymization attacks and build guardrails that make models refuse deanonymization requests.
Of course, another option is for people to dramatically curb their use of social media, or at a minimum, regularly delete posts after a set time threshold.
If LLMs’ success in deanonymizing people improves, the researchers warn, governments could use the techniques to unmask online critics, corporations could assemble customer profiles for “hyper-targeted advertising,” and attackers could build profiles of targets at scale to launch highly personalized social engineering scams.
“Recent advances in LLM capabilities have made it clear that there is an urgent need to rethink various aspects of computer security in the wake of LLM-driven offensive cyber capabilities, the researchers warned. “Our work shows that the same is likely true for privacy as well.”







{kind=link}