
Another day, another AI model from Google. This time, Google DeepMind has released a new member of the Gemma 4 open model family, but it’s fundamentally different from the rest of the lineup. DiffusionGemma doesn’t generate outputs linearly like most AI models. Instead, it can produce an entire block of text in parallel. Google says this makes it faster and more efficient when running on local hardware like an Nvidia DGX or a humble gaming GPU.
Most AI models are designed to be autoregressive—they generate text left to right one token at a time. DiffusionGemma has more in common with image generation models, which start with static and then denoise it to create the desired content. This model takes a field of placeholder tokens running over the canvas multiple times to generate likely tokens and using those to improve estimation of others. At the end of the process, the model finalizes its token outputs in one large block—the “denoised” text canvas.
DiffusionGemma is fairly large in the realm of Google’s open models. It’s a Mixture of Experts (MoE) model with a total of 26 billion parameters, but only 3.8 billion are activated during inference. That means it should fit in the 18GB RAM allotment of a high-end GPU. In testing with an RTX 5090, DiffusionGemma spits out around 700 tokens per second. With a single Nvidia H100 AI accelerator, DiffusionGemma can produce 1,000+ tokens per second. That’s about four times the output of the similarly sized autoregressive Gemma models.
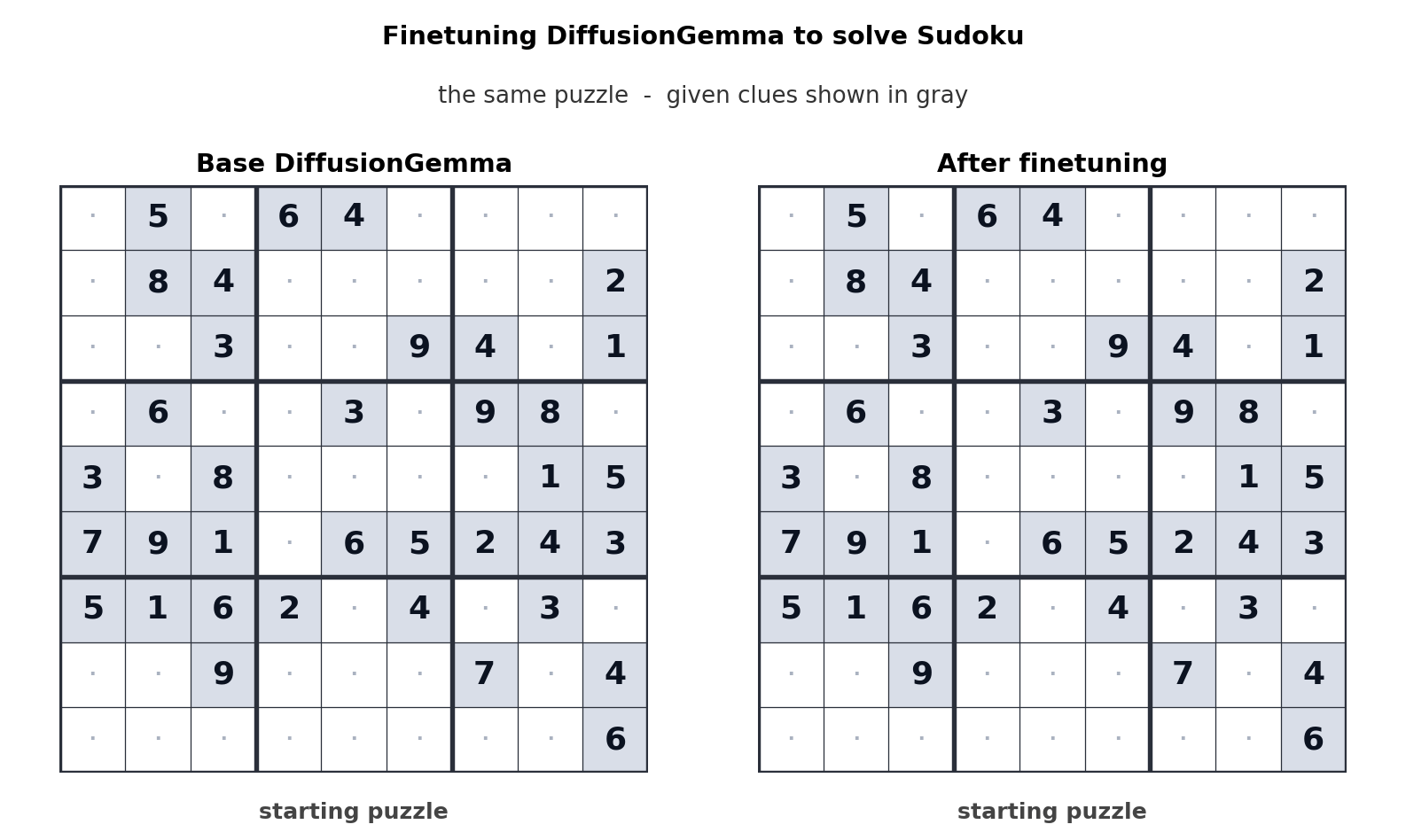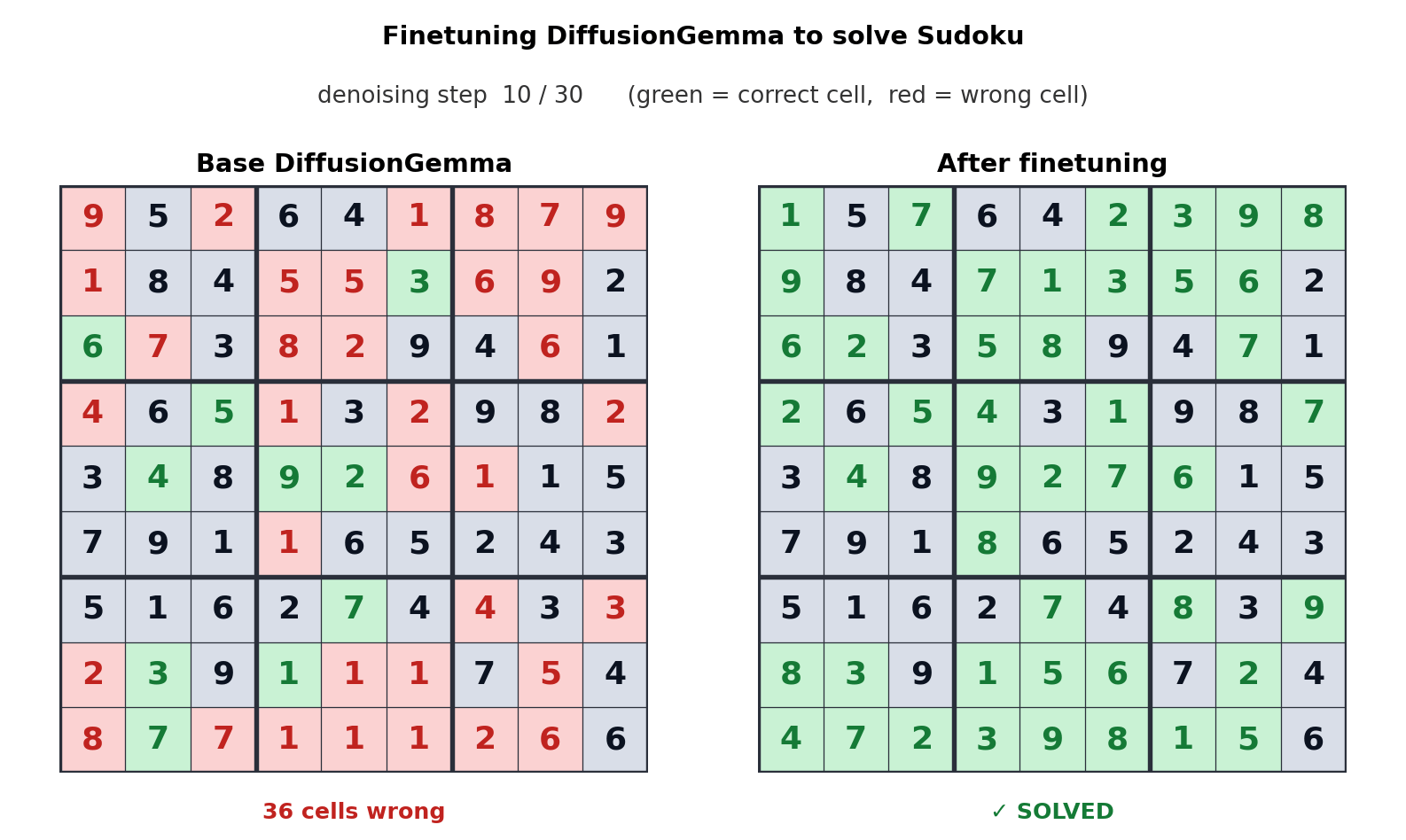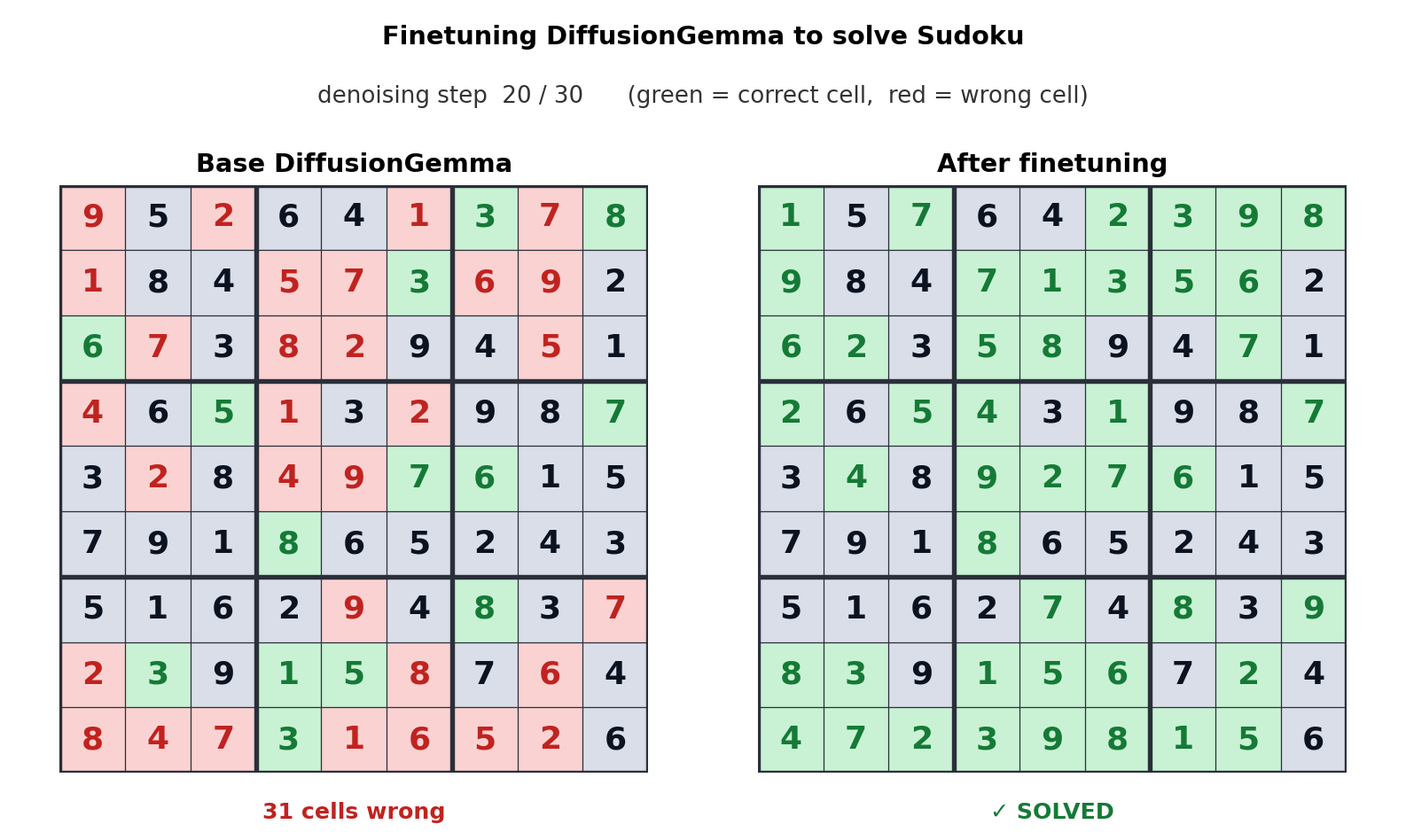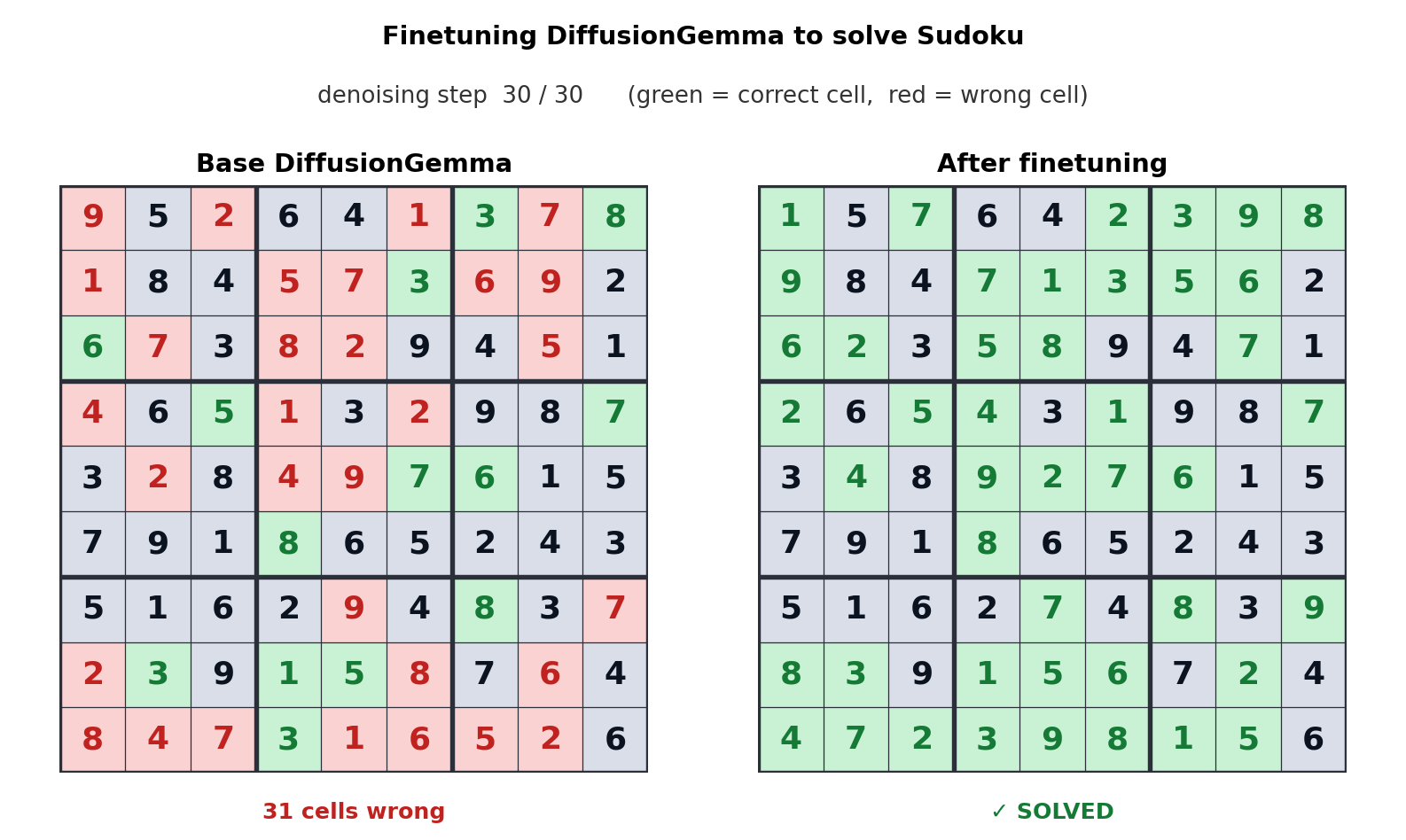
This approach to text generation shifts the bottleneck from memory bandwidth to compute, generating up to 256 tokens in parallel. Google says this offers a measurable boost in non-linear tasks like in-line editing, molecular sequencing, and mathematical graphing. The animation above shows how DiffusionGemma was tuned to solve Sudoku puzzles, which is a notoriously challenging task for standard autoregressive AI models because each token depends on future tokens. DiffusionGemma’s ability to continuously self-correct large sets of tokens makes that easier.
Multiple paths to local efficiency
If diffusion is so much faster, why isn’t Google using it in big cloud-based Gemini models? Google has experimented with this, but there are a few drawbacks to text diffusion, including a higher error rate. In image diffusion models, a single badly predicted pixel doesn’t make the image useless, but language is discrete. An equivalent error in text can make a block of tokens meaningless and force you to start over to get a better output. Diffusion models also waste resources when the desired output is only a few tokens long. They have to do a lot more parallel work to whittle down to, say, five tokens that an autoregressive model does from beginning to end in just five steps.
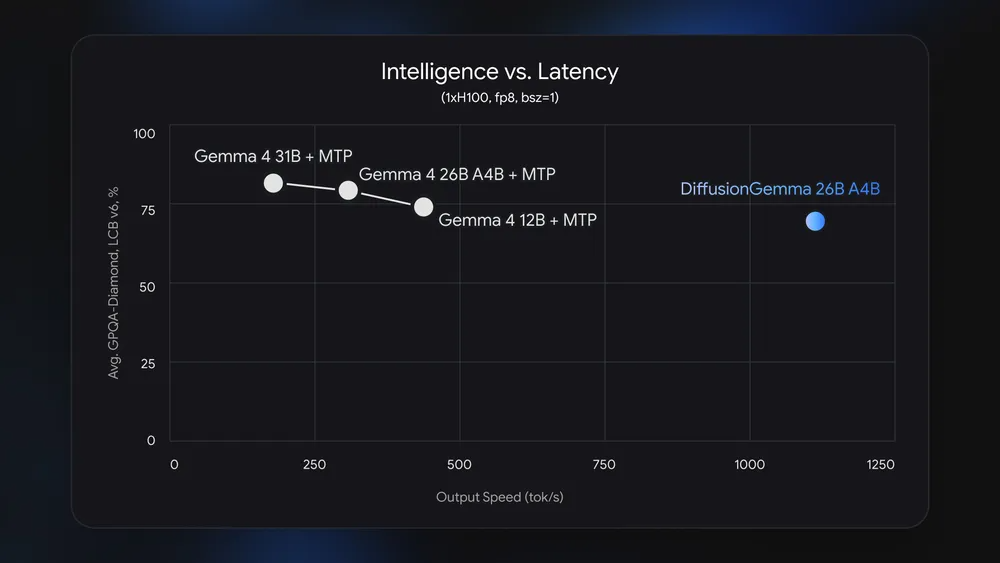
The efficiency gain for local processing makes this an appealing avenue of experimentation, though. In the cloud, autoregressive models can batch large numbers of compute jobs from multiple users so they’re always churning out tokens, and the high bandwidth memory (HBM) used in these systems can move data around much more efficiently.
Conversely, local AI encounters wasted compute cycles due to lower memory bandwidth and idle time. Diffusion models can make more efficient use of available compute, but this isn’t the only way. Google also recently began implementing Multi-Token Prediction (MTP) drafters, which use otherwise wasted compute cycles to predict possible tokens to increase speed. But diffusion is even faster than the MTP versions of Gemma.
Google stresses that DiffusionGemma is experimental, but it’s available under the same Apache 2.0 license as all the other fourth-generation Gemma models. You can download the model weights today from Hugging Face. Google says it worked with Nvidia to ensure DiffusionGemma was optimized for a variety of setups, including high-end RTX GPUs (quantized) and enterprise systems like the H100 or DGX Spark platform.







{kind=link}